Estadística aplicada a la investigación en salud
← vista completaPublicado el 1 de agosto de 2011 | http://doi.org/10.5867/medwave.2011.08.5102
Comparación del promedio de una muestra con el promedio del universo
Comparison of the mean of a sample with the average of the universe
Resumen
En la sección Series, Medwave publica artículos relacionados con el desarrollo y discusión de herramientas metodológicas para la investigación clínica, la gestión en salud, la gesión de la calidad y otros temas de interés. En esta edición se presentan dos artículos que forman parte del programa de formación en Medicina Basada en Evidencias que se dicta por e-Campus de Medwave. El artículo siguiente pertenece a la Serie "Estadística Aplicada a la Investigación en Salud".
En el contexto de la prueba de la hipótesis para comparar una muestra con el universo, el problema para el investigador podría ser el siguiente: en una población determinada, el peso de nacimiento promedio es 3,38 kilos y la desviación estándar 0,42 kilos. Se sospecha que los hijos de madres adolescentes tienen un peso de nacimiento diferente, probablemente menor.
En una muestra de 25 recién nacidos de madres adolescentes se obtuvo un promedio de peso al nacimiento de 2,85 kg, con una desviación estándar de 0,5 kg. ¿Se puede aceptar la hipótesis de que esta muestra pertenece a una población cuyo promedio y desviación estándar son, respectivamente, 3,38kg y 0,42kg?
Se identifican entonces los elementos del problema:
- Promedio del universo u0=3,38
- Promedio de la muestra x0=2,85
- Desviación estándar del universo o=0,42
- Desviación estándar de la muestra s=0,5
- Tamaño de muestra n=25
Una vez identificados los datos del problema, se buscará la solución guiados por el esquema básico.
Planteamiento de hipótesis en términos estadísticos
![]()
Esta hipótesis (hipótesis nula) plantea que la muestra, aunque tiene un promedio diferente, proviene de un universo cuyo promedio es 3,38 y que la diferencia entre el promedio de la muestra y el promedio del universo está dentro del error de muestreo.
![]()
Esta hipótesis (hipótesis alternativa) plantea que la muestra no proviene de este universo, ya que la diferencia entre el promedio de muestra y el promedio del universo es mayor que el error de muestreo (recuerde el error de los intervalos de confianza).
Elegir el nivel de significación
Elegimos un nivel de significación a=0,05. Este valor lo fija el investigador y debe ser menor o igual a 0,05.
Calcular el estadístico de prueba
Como se conoce la desviación estándar del universo (o) el estadístico para someter a prueba esta hipótesis será Z y su fórmula de cálculo es:
![]()
Llevando los datos del problema a la fórmula del estadístico se obtiene:
![]()
Entonces, el valor del estadístico de prueba es -6,3.
4. Buscar en la tabla normal la probabilidad de ocurrencia que tiene un valor de z igual o inferior a -6,3
Vemos en la tabla que el máximo valor de z que aparece es -3,49 y que la probabilidad de encontrar un valor igual o inferior a -3,49 es 0,0002 (probabilidad de la cola).
5. Comparar la probabilidad obtenida en la tabla con el nivel de significación elegido en el punto 2 y tomar una decisión respecto de las hipótesis planteadas
Dado que el valor de Z calculado (-6,3) está en un extremo de la curva, la probabilidad de obtener un valor igual o inferior a él es menor que la mitad del nivel de significación elegido (a/2=0,025). El hecho de que la probabilidad asociada al estadístico de prueba sea menor que la mitad del nivel de significación nos conduce a la decisión de rechazar la hipótesis nula (según el criterio enunciado).
6. Elaborar una conclusión derivada de dicha decisión
Ya que rechazamos la hipótesis nula, que plantea que la muestra observada pertenece a un universo con promedio 3,38 kg, podemos afirmar lo contrario, es decir que: “la muestra de 25 RN no pertenece al universo con promedio 3,38, sino que pertenece a un universo cuyo promedio es distinto de 3,38”. Esta afirmación se hace con un nivel de significación de 0,05.
7. Apoyar todo el proceso de análisis con un buen gráfico del problema
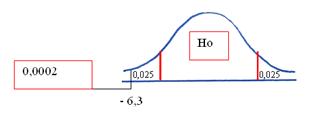
Se observa en el gráfico que la probabilidad asociada al valor del estadístico de prueba es inferior a la mitad del nivel de significación; lo que indica que la diferencia entre la muestra y el universo es significativa.
Supongamos ahora que el investigador no tiene información sobre la desviación estándar del universo. En ese caso la única diferencia en la solución estará en la obtención del estadístico de prueba, que en vez de usar la fórmula de “z” deberá usar la fórmula de “t”.
![]()
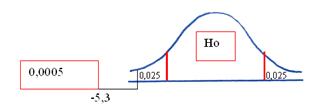
Buscamos en la tabla “t”, con 24 grados de libertad, la probabilidad asociada a este valor.
Mirando la tabla, en la fila de los 24 grados, se observa que el último valor a la derecha es 3,745. Subiendo desde este valor hasta la primera fila de la tabla encontramos que la probabilidad asociada a los valores superiores a 3,745 es 0,0005. Como la curva es simétrica se supone que ambas colas tienen igual probabilidad, por lo tanto podemos asociar también a -3,745 una probabilidad de 0,0005.
Finalmente, como la probabilidad del estadístico de prueba (0,0005) es menor que la mitad del nivel de significación (0,025), nuestra decisión de rechazo de la hipótesis nula se mantiene y por consiguiente también se mantienen las conclusiones.