Notas metodológicas
← vista completaPublicado el 7 de noviembre de 2019 | http://doi.org/10.5867/medwave.2019.10.7716
Conceptos generales en bioestadística y epidemiología clínica: estudios observacionales con diseño de casos y controles
General concepts in biostatistics and clinical epidemiology: observational studies with case-control design
Resumen
Los estudios de casos y controles han sido esenciales en el desarrollo de la epidemiología y de la salud pública. En este diseño, el análisis de los datos se realiza desde el desenlace hacia la exposición, es decir, retrospectivamente, ya que se estudia la asociación entre factores de exposición y un desenlace conocido entre personas que ya presentan una condición (casos) y quienes no la presentan (controles). Por lo tanto, son muy útiles en condiciones infrecuentes o que requieren una larga latencia para ocurrir. Existen distintas metodologías de selección de casos, pero el aspecto central es la adecuada selección de controles. La recolección de los datos puede ser retrospectiva (desde de registros clínicos) o prospectiva (mediante la aplicación de instrumentos de recolección de datos a los participantes). En función del objetivo del estudio, se dispone de distintos tipos de estudios de casos y controles, pero todos presentan una vulnerabilidad particular al sesgo de información y de confusión, los que pueden controlarse a nivel del diseño y del análisis estadístico. En este artículo se abordan conceptos teóricos generales sobre los estudios de casos y controles, considerando aspectos históricos, metodología de selección de participantes, tipos estudios de casos y controles, medidas de asociación, potenciales sesgos, ventajas y desventajas. Finalmente, se discuten algunos conceptos de relevancia sobre este diseño para los estudiantes de pre y posgrado de ciencias de la salud. Esta revisión es la tercera entrega de una serie metodológica sobre conceptos generales en bioestadística y epidemiología clínica desarrollada por la Cátedra de Metodología de la Investigación Científica de la Escuela de Medicina de la Universidad de Valparaíso, Chile.
Ideas clave
- Los estudios de casos y controles analizan la asociación entre factores de exposición y personas que presentan (casos) y no presentan (controles) un desenlace de interés. Estudian desde el efecto (outcome) hacia las causas.
- Son útiles en condiciones infrecuentes o que requieren una larga latencia para ocurrir, pero son sensibles a los sesgos de información y confusión.
Introducción
Durante el siglo XIX, ciertas investigaciones ya incluían algunos elementos del diseño de casos y controles. Probablemente, el ejemplo modélico es el de la historia de John Snow y el Reverendo Henry Whitehead con sus investigaciones sobre los brotes de cólera en relación con la fuente de Broad Street[1],[2]. A diferencia de Snow, Whitehead se dedicó a evaluar la exposición a agua de la fuente en individuos sin cólera (controles). Mediante una encuesta acuciosa y sistemática, que incluía visitar a una persona hasta cinco veces, recopiló información básica pero relevante respecto del consumo de agua entre residentes de Broad Street, concluyendo que el uso del agua de la fuente se asociaba con la presencia de cólera, lo que repercutió en una disminución de 127 muertes el 2 de septiembre de 1854 a 30 el día 8 de septiembre[3].
Sin embargo, la concepción moderna del diseño de casos y controles se reconoce en el estudio sobre factores asociados al cáncer de mama de Janet Lane-Claypon en 1926[4]. En 1939, otro estudio de casos y controles encabezado por Franz Müller[5], miembro del partido Nazi, vinculaba el consumo de cigarrillos con el cáncer de pulmón, lo que iba en concordancia con el sentimiento antitabaco de Hitler. En efecto, durante su gobierno se promovieron campañas propagandísticas en contra del consumo de tabaco a la luz de la reciente evidencia disponible en cuanto a sus efectos. Müller envió un cuestionario a familiares de víctimas del cáncer pulmonar, preguntando acerca del patrón de consumo, su forma y temporalidad, además del tipo de tabaco usado, corroborando una fuerte asociación entre el consumo de tabaco y la enfermedad[5],[6]. A continuación, y paralelo al curso de la Segunda Guerra Mundial, hubo un detenimiento teórico en el desarrollo de este diseño metodológico hasta 1950, año en que se publicaban cuatro estudios de casos y controles que analizaban la relación entre tabaquismo y cáncer pulmonar, validando su uso en el estudio de la etiología de las enfermedades. Uno de ellos es el estudio desarrollado por Richard Doll y Austin Bradford Hill[7],[8], quienes argumentaban que el aumento en las tasas de cáncer pulmonar observados en Gales e Inglaterra, no se explicaba completamente por un mayor desarrollo de la calidad de las pruebas diagnósticas, como se esgrimía en la época, sino que a factores ambientales como el tabaquismo y la polución ambiental7.
Unas décadas más tarde, en 1987, se publicaba un estudio sobre los factores asociados a la transmisión del síndrome de inmunodeficiencia adquirida, tales como la promiscuidad y el uso de drogas endovenosas[9],[10]. El conocimiento de estos factores de riesgo permitió la implementación de medidas que redujeron la transmisión del virus, incluso antes de que fuese identificado[10].
De este modo, la epidemiología comenzaba a priorizar el análisis de factores de riesgo por sobre el estudio de causas suficientes y necesarias[1], pues ya Snow había declinado en la búsqueda de un agente microscópico para el cólera, poniendo en primer lugar el esclarecer las vías en que la enfermedad se transmitía de persona a persona[3]. De este modo, para estudiar la etiología y los factores pronósticos (factores protectores y factores de riesgo), la epidemiología observacional ha desarrollado los estudios de casos y controles y los estudios de cohorte[11]. En esta revisión nos centraremos en el primer diseño, pues el análisis de los estudios de cohorte corresponderá al siguiente artículo de esta serie metodológica.
Este artículo corresponde a la tercera entrega de una serie metodológica de seis revisiones narrativas acerca de tópicos generales en bioestadística y epidemiología clínica, las que explorarán artículos publicados disponibles en las principales bases de datos y textos de consulta especializados. La serie está orientada a la formación de estudiantes de pre y posgrado, y es realizada por la Cátedra de Metodología de la Investigación Científica de la Escuela de Medicina de la Universidad de Valparaíso, Chile. Por lo tanto, el objetivo de este manuscrito es abordar los principales conceptos teóricos y prácticos de los estudios de casos y controles.
Conceptos preliminares del diseño
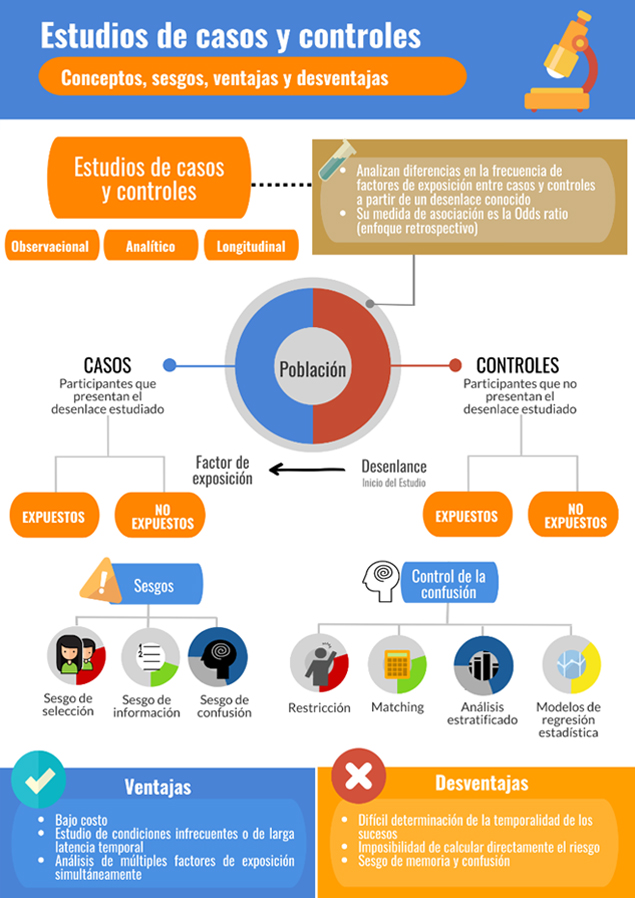
Los estudios de casos y controles constituyen un diseño observacional, analítico y longitudinal: el investigador no interviene la variable de exposición, el diseño permite la realización de pruebas de hipótesis estadística y existe un seguimiento en el tiempo de los individuos y variables de interés. Incluso, algunos autores plantean que podrían demostrar relaciones causales más allá de meras asociaciones entre variables[12], siendo esto un motivo controvertido. Para su realización, se recluta a un grupo de participantes que presentan un desenlace de interés, usualmente una enfermedad (casos), y a un grupo que no lo presenta (controles), similares en sus características basales. En ambos conjuntos se estudian variables conceptualizadas como factores de riesgo y se compara su nivel de exposición. Entonces, una característica fundamental de un estudio de casos y controles es que los sujetos son seleccionados según el desenlace, lo que reviste una ventaja al pensar que no es necesario esperar un gran espacio de tiempo para que ocurra el fenómeno que se quiere estudiar, pero al mismo tiempo una desventaja, ya que muchas veces los datos tendrán que recogerse también retrospectivamente, por lo que su calidad dependerá de un adecuado registro y aun de la memoria de los participantes[13].
Selección de los casos
La selección de los casos debe ser rigurosa, privilegiando los casos incidentes (casos que hayan sido diagnosticados recientemente) por sobre los casos prevalentes (casos que lleven un largo tiempo de diagnóstico), puesto que los casos incidentes son más similares y consistentes con la realidad actual que aquellos casos antiguos, donde por ejemplo, los criterios diagnósticos podrían haber sido otros.
En este sentido, es necesario contar con una definición clara del desenlace a estudiar (por ejemplo, criterios diagnósticos internacionales y actuales, exámenes de laboratorio, estudios imagenológicos, entre otros) y de los otros criterios de inclusión y exclusión, tales como lugar de selección (por ejemplo, servicio hospitalario o ciudad desde la cual se obtuvo a los participantes) y rango etario[14],[15].
Según su lugar de obtención, encontramos casos hospitalarios, casos poblacionales o comunitarios y casos de grupos especiales (por ejemplo, desde agrupaciones como Alcohólicos Anónimos o sociedades de pacientes con alguna enfermedad genética). Los casos hospitalarios pudiesen ser fáciles de conseguir, pues se emplea el registro de personas ya existente en un centro de salud; sin embargo, podrían no ser representativos del grupo de personas con la enfermedad. Por su parte, los casos poblacionales son infrecuentes debido a la dificultad que implica encontrarlos sin contar con registros clínicos, como sucede la mayoría de las veces, pero ventajosamente se disminuiría el sesgo de selección y mejoraría la validez interna y la capacidad de generalización de los resultados, ya que la selección comunitaria sería cercana a lo que sucede realmente con la patología[16].
Selección de los controles
La selección de controles corresponde al hito más importante del desarrollo de un estudio de casos y controles, pues en ella descansa la validez interna de la investigación. Los controles representan la frecuencia basal de exposición en individuos libres del desenlace en estudio. Sin embargo, no necesariamente deben ser absolutamente sanos, pues una persona enferma por otra causa puede desarrollar igualmente la condición de interés[17]. Lo fundamental es que estén libres del desenlace en estudio y su selección debe siempre realizarse independientemente de la presencia o no del factor de exposición que se analiza.
Los controles deben ser representativos de la población desde la cual se obtuvo a los casos, es decir, deben extraerse desde la misma base poblacional (regla conocida como “principio de base del estudio”)[16], de modo de presentar el mismo riesgo de exposición que los casos y evitar el sesgo de selección. La mejor forma de garantizarlo es seleccionarlos mediante un muestreo aleatorio, lo que aseguraría que los controles hayan tenido la misma probabilidad teórica que los casos de haber estado expuestos al factor de riesgo[18]. La cantidad de controles por cada caso no debería exceder a tres o cuatro, pues se ha demostrado que por sobre esta cantidad el incremento de la potencia del estudio es mínima pero el de costos es desproporcionado[17],[19]. Lo anterior responde al “principio de eficiencia”, tanto estadística (lograr una potencia adecuada) como operacional (optimizar el uso del tiempo, energía y recursos de la investigación)[16].
Los controles pueden hallarse en un grupo conocido, esto es un grupo observado durante un periodo. No obstante, el grupo del que provienen los casos es usualmente desconocido[20], por lo que su determinación puede ser previa a la delimitación del grupo desde donde se seleccionarán los participantes.
En este sentido, como no se conoce la base poblacional de los casos, la selección de los controles sucedería igualmente desde un grupo desconocido. Para ello se han sugerido algunas estrategias, como el seleccionar controles que sean vecinos del lugar de residencia de los casos[17]. Asimismo, se ha propuesto que los controles puedan ser amigos (compartirían características como el nivel socioeconómico y educacional) o familiares de los casos (compartirían características genéticas y de estilos de vida). La selección puede hacerse también a partir de controles hospitalarios, lo que es conveniente si se piensa que provendrían desde el mismo centro de salud de los casos y además tendrían motivación por participar debido a una conducta similar en cuanto a la búsqueda de cuidado en su salud mayor al de los controles obtenidos desde la comunidad[20]. No obstante, una desventaja es que no podría asegurarse que los controles hospitalarios tengan una probabilidad similar que los casos de haber estado expuestos al factor que se está analizando[17].
Una vez seleccionados los casos y los controles, debe determinarse la proporción de exposición a los factores de riesgo estudiados en ambos grupos. Estos datos pueden determinarse al revisar las fichas clínicas de los participantes del estudio o también mediante la aplicación de cuestionarios. Es de suma relevancia, para no incurrir en sesgos como se analizará más adelante, el que los datos se busquen con la misma acuciosidad en casos y controles. Finalmente, y como es de esperar, en la medida de que la diferencia en la proporción de expuestos a un factor de riesgo entre los grupos sea mayor, mayor será también la probabilidad de que exista una asociación entre el desenlace y dicho factor[11].
Medidas de asociación
Por la naturaleza del diseño de casos y controles, la medida de asociación se estima en relación con un evento ya ocurrido, comparándose la frecuencia de exposición entre casos y controles, además de otros estimadores. Debido a esta naturaleza retrospectiva del evento, no es posible calcular el riesgo relativo, sino que se estima la Odds ratio (también conocida como razón de momios, razón de probabilidades, razón de ventajas, razón de disparidad, razón de productos cruzados, entre otros), asociada a sus intervalos de confianza[10].
Esta medida representa el cociente entre la chance (Odds ratio) de exposición en el grupo de casos y en el grupo de controles, interpretada como cuántas veces más posibilidades tienen los casos de haber estado expuestos al factor estudiado en comparación con los controles (debe interpretarse de esta manera y no como un riesgo relativo directo)[16]. No obstante, la Odds ratio es una buena estimación del riesgo relativo cuando la tasa de incidencia del desenlace en estudio es baja (no mayor a 5 o10% tanto en expuestos como no expuestos), lo que se ha conocido como el supuesto de enfermedad rara (rare disease assumption)[16].
La Odds ratio tiene una interpretación similar (pero no igual) al riesgo relativo, tomando valores que van del cero al infinito. Una Odds ratio menor a 1 indica que la exposición se comporta como un factor protector para presentar el desenlace, mientras que si fuera mayor a 1 se trataría un factor de riesgo, es decir, aumenta la probabilidad de que el desenlace ocurra. Finalmente, si su valor fuera igual a 1, podría deducirse que no existe asociación entre el factor de exposición y el desenlace[21] (Ejemplo 1)[1].
Mediante el diseño de casos y controles no puede calcularse directamente la incidencia ni la prevalencia de una condición. No obstante, una excepción serían los estudios de casos y controles poblacionales, donde se reconoce que la prevalencia de exposición del grupo control es representativa de toda la población y la incidencia poblacional de la variable a estudiar es conocida, lo que permitiría la estimación de la incidencia. Esta estimación sería posible en estudios de casos y controles anidados en una cohorte y en estudios de casos-cohorte[15], diseños que se definirán a continuación.
Tipos de estudios de casos y controles
En la literatura existen múltiples variantes de los diseños metodológicos tradicionales que pueden satisfacer de mejor manera las necesidades y las posibilidades de la investigación y del investigador. A continuación, se refieren las principales características de algunas variantes según el método de selección de casos.
Estudios de casos y controles basados en casos
Este diseño corresponde a la forma tradicional y más frecuente de un estudio de casos y controles. Se reclutan casos ya existentes (casos prevalentes) o nuevos (casos incidentes), conformando un grupo control a partir de la misma base o cohorte hipotética (hospitalaria o poblacional)[16].
Estudio de casos y controles anidados en cohorte
En este diseño, el muestreo de casos se realiza desde una cohorte, es decir, desde un estudio prospectivo en donde todos los participantes se encontraban inicialmente sin el desenlace de interés. Una vez que lo presentan, se transforman en casos incidentes que pueden nutrir a un estudio de casos y controles anidado, para luego efectuar el análisis de los factores a los que estuvo expuesto cada grupo. Paralelamente, los controles provienen desde la misma cohorte y se seleccionan mediante un muestreo aleatorio, realizando un emparejamiento de acuerdo con la duración de seguimiento. Este tipo de estudio es conveniente por contemplar un mejor control de los factores de confusión, pues la cohorte constituye un grupo homogéneo definido en espacio y en tiempo. Esto significa que la plataforma desde la cual se obtienen los participantes es bien conocida. También, permite una mejor cuantificación de los efectos de las exposiciones dependientes del tiempo, ya que se sabe con mayor precisión cuándo se presentó el desenlace[15],[18].
Estudios de casos cruzados, caso-caso o autocontrolados (case-crossover studies)
En este diseño metodológico de reciente desarrollo, los antecedentes de exposición de cada paciente se usan para su propio control, lo que pretende eliminar las diferencias interpersonales que generan confusión[22]. Esto es, cada caso es su propio control[23], por lo que se trata de un tipo de diseño pareado[24]. Estos estudios son útiles en el análisis de exposiciones transitorias, tales como un periodo de mal dormir como factor de riesgo para sufrir un accidente automovilístico[23], donde se definiría un “periodo de caso”, que puede comprender las 48 horas previas al accidente, y un “periodo control”, que podría abarcar entre las 72 y las 49 horas previas. Una desventaja importante es que este modelo supone que no existe un efecto de continuación de la variable de exposición una vez que ha cesado (carry-over).
Estudios de casos-cohorte
Corresponde a un diseño mixto, que involucra características de un estudio de casos y controles y de un diseño de cohorte, no obstante, es más cercano metodológicamente a este último[25]. Los estudios de casos-cohorte se analizarán en la próxima entrega de esta serie metodológica, que corresponde a estudios de cohorte.
Sesgos
En los estudios de casos y controles, la característica que condiciona de forma más importante a la aparición de sesgos es que el análisis se inicia desde el desenlace y no desde la exposición, obteniéndose la información mayoritariamente de manera retrospectiva. Igualmente, deben considerarse sesgos a los que puede incurrirse durante la planificación del estudio, como el subvalorar el costo económico del estudio, lo que puede imposibilitar una apropiada finalización[26].
Sesgo de selección
El sesgo de selección se asocia a una ausencia de comparabilidad (falta de similitud) entre los grupos estudiados. Es decir, los casos y los controles difieren en sus características basales, medidas o no medidas, debido al método en que son seleccionados. Por ende, es necesario asegurar que los casos y los controles sean similares en todas las características importante excepto en el desenlace estudiado[27]. Un ejemplo es el sesgo de Berkson, también conocido como sesgo de admisión, paradoja o falacia de Berkson[26],[27]. Éste resulta de una diferencia sistemática en la selección de casos hospitalarios, ya que en ocasiones la combinación entre un factor de exposición y el desenlace estudiado hace variar el riesgo de ingreso a un hospital (Ejemplo 2)[28].
Otro tipo de sesgo de selección es el sesgo de Neyman[26],[27], también llamado de prevalencia, de incidencia o de sobrevida. Aparece cuando una determinada condición produce muertes prematuras que impiden que estos participantes puedan incorporarse al grupo de casos, lo que puede redundar en que no se obtenga una asociación debido a la falta de incorporación en el análisis de los participantes que ya han muerto. Por lo tanto, se genera un grupo de casos que no es representativo de los casos comunitarios. Esto es lo que ocurre con enfermedades que son rápidamente fatales, subclínicas o transitorias (Ejemplo 3).
Sesgo de información
También denominado sesgo de observación, clasificación o medición. Aparece cuando hay una determinación incorrecta de la exposición o del desenlace[27]. En los estudios de casos y controles, la información sobre la exposición debe recabarse de la misma manera en ambos grupos (lo que se conoce como “principio de precisión comparable”[16]) e idealmente por personas entrenadas y que no conozcan a qué grupo pertenecen los respondedores, ya que de saberlo, pueden provocar que cierta información sea respondida diferencialmente entre grupos, lo que se ha conocido como sesgo del entrevistador[14].
Un tipo de sesgo de información de gran importancia en este diseño es el sesgo de memoria o de recuerdo, debido a que los datos muchas veces provendrán desde el recuerdo que tengan los participantes de la exposición. Los casos tienden a buscar en su memoria los factores que puedan haber causado su enfermedad, pero los controles no tienen esta motivación, por lo que suele referirse que los casos recuerdan de mejor manera que los controles[17].
Como solución se ha propuesto que se seleccionen controles con enfermedades similares a la de estudio; por ejemplo, si el grupo de casos tiene el cáncer A, los controles podrían tener el cáncer B, de modo de que ambos grupos estén familiarizados y sensibilizados con la información que se recabará. Este procedimiento es válido siempre y cuando se corrobore que la exposición en estudio no se relaciona con la patología presente en el grupo control, pues de lo contrario se sumaría aun más sesgo. Otros métodos recomendados son el uso de fotografías, calendarios, periódicos o cualquier material que ayude a clarificar los recuerdos de la exposición en los participantes[10].
Sesgo de confusión
El fenómeno de confusión ya ha sido discutido en dos artículos previos de esta serie metodológica[29],[30]. Se nombrarán estrategias de control de la confusión a nivel del diseño metodológico (restricción y matching) y del análisis estadístico (análisis estratificado, regresión estadística y puntaje de propensión).
El procedimiento de restricción corresponde a la selección estricta de sujetos que presenten la característica que se quiere “neutralizar” o bien que no la presenten. Si bien ayudaría a aumentar la validez interna (por disminuir la probabilidad de sesgo), disminuiría su validez externa, ya que los resultados serían más difíciles de extrapolar[27].
Otro modo de aminorar el efecto de la confusión es el pareo, emparejamiento o matching. Comprende la selección de participantes que comparten la característica que se busca neutralizar, por ejemplo, nivel socioeconómico o grupo etario[31]. Tal sería el caso de un estudio que busque comparar a un grupo de mujeres con y sin esclerosis múltiple. Si la primera participante es portadora de la enfermedad, tiene 40 años y es de un estrato socioeconómico alto, el control correspondiente sería una mujer de las mismas características, pero sin la enfermedad. Esto se detalla en el Ejemplo 4, a partir de las investigaciones de Lane-Claypon[4],[6] y de Müller[5].
Hay que tener en mente algunos aspectos dificultados por el matching: impedirá el análisis del efecto de las variables que se hayan pareado[27] y puede incrementar el tiempo y el costo del estudio cuando no se encuentran los controles apropiados para los casos[32]. Por tanto, el emparejamiento debe realizarse en virtud de una variable que se catalogue como un potencial factor de confusión, ya que de no ser así, se pierde eficiencia y se disminuye la validez de la comparación entre casos y controles, fenómeno conocido como sobre emparejamiento (overmatching)[33], perdiendo la opción de detectar diferencias que debieron haber sido detectadas. Por lo tanto, se ha sugerido que el emparejamiento no sea un proceso obligatorio en los estudios de casos y controles, considerándose sobre todo en caso de muestras muy pequeñas o de exposiciones muy raras[16].
El análisis estratificado puede entenderse como una forma post hoc de restricción, ya que el estudio de las variables puede estratificarse según distintos niveles de una eventual variable de confusión. Esto es demostrado en la paradoja de Simpson[16], la que muestra que la medida de asociación (Odds ratio) entre exposición y desenlace es diferente cuando se compara al grupo completo que al comparar a estratos o subconjuntos del grupo de casos y del grupo de controles definidos en función de una característica, como rango etario, sexo, entre otros, por lo que podría suponerse que la variable de estratificación puede actuar como factor confusional.
El análisis estadístico de la estratificación corresponde al procedimiento de Mantel-Haenszel, el que determina si existe asociación entre un factor de exposición y un desenlace controlando el efecto de uno o más factores de confusión. Si el efecto ajustado por el método de Mantel-Haenszel difiere significativamente del efecto “crudo” o no ajustado, se presume que el factor de confusión está presente[14],[27]. La estratificación podría verse limitada por el tamaño muestral, puesto que, al analizar diversos estratos por separado, cada grupo podría conformarse por un número muy reducido de observaciones. Un caso de análisis estratificado se cita en el Ejemplo 5.
Como ha sido referido en entregas previas de esta serie[29],[30], las variables de confusión pueden identificarse también mediante modelos multivariados de regresión estadística. Su objetivo es ajustar un modelo de predicción para una variable dependiente a partir del efecto de múltiples variables independientes[34],[35].
Finalmente, en estudios observacionales se ha aplicado el puntaje de propensión (propensity score)[36], una metodología estadística cuya finalidad es reducir la confusión por indicación (sesgo de selección)[37]. Este puntaje corresponde a la probabilidad de exposición a un factor estimado a partir de un conjunto de variables observadas que pueden influenciar la probabilidad de exposición (a mayor puntaje, mayor será la probabilidad de exposición). De este modo, los subgrupos de análisis pueden categorizarse en función de este puntaje o, en modelos de regresión estadística multivariados, el puntaje de propensión puede incluirse como una covariable del modelo[35]. Es importante contemplar que, pese a los procedimientos llevados a cabo en el diseño y el análisis de un estudio, puede persistir algún nivel de confusión residual no conocida, particularmente si se trata de estudios observacionales[31].
Ventajas y desventajas
Los estudios de casos y controles constituyen el mejor diseño epidemiológico para investigar enfermedades infrecuentes y que se expresan en brotes (tal como el estudio sobre cólera asociado a la fuente de Broad Street). Suelen conducirse con rapidez, puesto que los desenlaces ya ocurrieron, obteniéndose resultados relevantes en un tiempo breve[10]. En este sentido, son útiles en patologías de larga latencia o incubación, ya que en un estudio de cohorte, por ejemplo, se requeriría de un largo periodo de tiempo para observar la aparición de la enfermedad. Otro aspecto bastante positivo es el que posibilitan el estudio de distintos factores de riesgo simultáneamente[11].
Una dificultad central es lo complejo que puede ser llegar a determinar la temporalidad de los sucesos, vale decir, si la causa precedió al efecto, como sería esperable. Pueden no detectar a pacientes que aún se encuentran incubando la patología y que han sido seleccionados como controles. Debido a la naturaleza retrospectiva de la secuencia de eventos, este tipo de estudios no permite calcular directamente el riesgo, puesto que solo puede definirse la proporción de personas con el desenlace que estuvieron expuestos en el pasado. Adicionalmente, cierto tipo de sesgos, como el de memoria, son particularmente prominentes[10],[14].
Consideraciones finales
La lectura de un estudio de casos y controles debe hacerse de manera concienzuda, pues puede resultar poco intuitivo el pensar en una asociación teniendo como punto de partida el desenlace y no los factores que la habrían desencadenado: la lectura de un artículo de casos y controles se inicia al finalizar la cadena de causalidad. Esto ha provocado que el diseño de casos y controles sea clasificado como “retrospectivo”, lo que para algunos autores sería inadecuado. Esto debido a que la información también puede recogerse prospectivamente por medio de la aplicación de instrumentos, de entrevistas o de otros métodos que apunten a la “reconstrucción de los hechos”, aunque el desenlace ocurrió en el pasado y la recolección de la información se realice por lo general retrospectivamente (historia clínica, bases de datos, entre otros). Por lo tanto, un estudio de casos y controles podría ser prospectivo desde el punto de vista de cómo se obtienen los datos, por lo que hay que clarificar si la clasificación temporal (retrospectivo o prospectivo) se hizo en función del diseño o de la recogida de datos[16].
Aunque se ha propuesto que para la selección de casos las definiciones diagnósticas deben ser claras y deben quedar refrendadas en los criterios de elegibilidad, debe tenerse en cuenta que múltiples y muy estrictos criterios de inclusión y de exclusión limitarán la validez externa o “generalizabilidad” de los resultados. Sin embargo, el estudio debe realizarse sobre la premisa de que la validez interna ocupa un lugar prioritario por sobre la validez externa, ya que la segunda depende de la primera[16].
Respecto a los controles, y aunque algunos autores han apoyado la idea de usar dos grupos de controles para un grupo de casos y luego, tras el análisis de datos, elegir el que presente las mejores características[17],[38], lo fundamental, más allá de la cantidad de grupos, es el elegir de la mejor manera posible a los controles: deben ser similares en todos los aspectos importantes a los casos a excepción de no portar la condición que se está estudiando. La elección de controles es fundamental, por lo que algunos autores han indicado que no deben aceptarse los resultados de un estudio de casos y controles hasta que el lector haga una evaluación de la rigurosidad con que con el grupo control fue seleccionado[14]. Para esto, la investigación debe ser correctamente comunicada en el artículo publicado, siguiendo las recomendaciones internacionales sintetizadas en la pauta de reporte STROBE (Strengthening the Reporting of Observational studies in Epidemiology) para estudios observacionales (http://www.strobe-statement.org/)[39].
Los estudios de casos y controles presentan diversas utilidades y fortalezas, demostrando en la historia haber sido la piedra angular del estudio de grandes problemáticas de salud pública. Sin embargo, su principal debilidad tiene que ver con que la exposición ocurrió en el pasado, lo que aumenta la ocurrencia de sesgos. Se ha propuesto controlar el efecto del sesgo de confusión mediante el análisis estratificado por técnicas de Mantel-Haenszel, pero como han estimado algunos autores, éste ha sido reemplazado en gran medida por los modelos multivariados de regresión estadística[40]. Lo mismo ha sucedido con el matching, cuya aplicación se ha visto un tanto disminuida a favor del uso de técnicas de regresión estadística[15],[16]. No obstante, siempre será una mejor opción el controlar los sesgos a nivel del diseño que del análisis estadístico. Así, el análisis estadístico más avanzado no salvará a un estudio mal diseñado: los controles deben seleccionarse con máxima rigurosidad.