Introducción a la medicina basada en evidencias
← vista completaPublicado el 2 de enero de 2010 | http://doi.org/10.5867/medwave.2011.01.4843
Concepto de asociación, causa y riesgo
Concept of association, causes, and risk
Resumen
En la sección Series, Medwave publica artículos relacionados con el desarrollo y discusión de herramientas metodológicas para la investigación clínica, la gestión en salud, la gestión de la calidad y otros temas de interés. En esta edición se presentan dos artículos que forman parte del programa de formación en Medicina Basada en Evidencias que se dicta por e-Campus de Medwave. El artículo siguiente pertenece a la Serie "Introducción a la Medicina Basada en Evidencias".
Asociación
En los estudios clínicos, el concepto de asociación se refiere a la existencia de un vínculo de dependencia entre una variable y otra. En general, la forma de identificar la asociación es a través de la comparación de dos o más grupos, para determinar si la frecuencia, magnitud o la presencia de una de las variables modifica la frecuencia de la otra en algún sentido.
Se puede asumir que la asociación encontrada en un estudio es real, cuando descartamos razonablemente que no se debe simplemente al azar (no ocurrió por razones fortuitas). Existen tests estadísticos que permiten evaluar este aspecto, que se expresan a través del conocido valor “p” y que abordaremos con más detalle en notas posteriores. Si los resultados del test sugieren que la asociación encontrada no se debe al azar (ej., p 0,05), hablamos de una asociación “estadísticamente significativa”.
El hallazgo de una asociación puede deberse también a un sesgo o error sistemático, o al efecto de una o más variables confusoras. Gran parte del esfuerzo de la epidemiología clínica tiene que ver con que esto no ocurra. Trataremos estos conceptos, algo más difíciles de asimilar en términos abstractos, al referirnos más adelante a los distintos diseños de investigación.
En términos prácticos, las principales asociaciones de interés clínico incluyen:
- La asociación entre un factor de riesgo (variable de exposición) y la aparición de enfermedad o sus desenlaces (variable de resultado). Por ejemplo: La asociación entre la historia personal de transfusiones (variable de exposición) y la infección crónica por hepatitis C (variable de resultado).
- La asociación entre un factor pronóstico (variable de exposición) y el curso de la enfermedad o sus desenlaces (variable de resultado). Por ejemplo: La asociación entre la presencia de hipertensión arterial (variable de exposición) y el desarrollo de insuficiencia renal crónica terminal en pacientes diabéticos (variable de resultado).
- La asociación entre una intervención preventiva o promocional (variable de exposición) y la aparición de enfermedad o sus desenlaces (variable de resultado). Por ejemplo: La asociación entre el uso de preservativo (variable de exposición) y el contagio del VIH (variable de resultado).
- La asociación entre una intervención terapéutica o rehabilitadora (variable de exposición) y el curso de la enfermedad o sus desenlaces (variable de resultado). Por ejemplo: La asociación entre el uso de levotiroxina (variable de exposición) y la calidad de vida en pacientes con hipotiroidismo (variable de resultado).
- La asociación entre otras formas de intervención sobre los pacientes, el personal de salud o sobre la comunidad (variable de exposición) y las conductas o actitudes de los sujetos sometidos a la intervención, o los desenlaces sanitarios que derivan de ello (variable de resultado). Por ejemplo: La asociación entre la educación sobre el lavado de manos al personal de salud (variable de exposición) y la tasa de infecciones intrahospitalarias (variable de resultado).
- La asociación entre una intervención (variable de exposición) y la ocurrencia de eventos adversos derivados de ella (variable de resultado). Por ejemplo: La asociación entre el uso de benzodiazepinas (variable de exposición) y la aparición de dependencia (variable de resultado).
En el lenguaje epidemiológico se utilizan también los términos variable “independiente” para referirse a la exposición, y variable “dependiente” (la que depende de la otra) para el resultado.
¿Porqué es importante utilizar un grupo de control en los estudios clínicos?
Cuando se intenta asociar una exposición (por ejemplo, el uso de un bloqueador H2 en pacientes con reflujo gastroesofágico, RGE) a un resultado (la mejoría de los síntomas en pacientes con RGE), y el estudio se realiza sobre un solo grupo de pacientes, se tiende a asumir que los resultados observados (ej., 80% de mejoría en los síntomas) estuvieron vinculados a la exposición.
Bajo esas condiciones, sin embargo, difícilmente podremos dilucidar si el resultado no se produjo simplemente como consecuencia de la evolución espontánea o de las fluctuaciones naturales del cuadro en esos pacientes, o si se debió a otros factores y no a la exposición propiamente tal (ej., a una modificación en los hábitos alimentarios de los pacientes).
Cuando no existe un grupo control, tampoco podemos comparar directamente el efecto de dos o más exposiciones alternativas (ej., bloqueador H2 vs. inhibidores de la bomba de protones). La existencia de un grupo control no expuesto, expuesto en un grado distinto, o a una variable distinta, resuelve estas limitaciones, porque permite calcular efectos netos, es decir, cómo se modifica la variable de resultado más allá de lo esperado en forma espontánea, o más allá del efecto de una exposición alternativa. Si el tratamiento con placebo produce un 30% de mejoría en los síntomas en los pacientes con RGE, y el omeprazol un 80%, el efecto neto del omeprazol es de un 50%, y no de 80%.
Lo mismo se aplica al estudio del pronóstico de las enfermedades en los estudios de cohorte. Si no disponemos de un grupo control, ¿cómo podemos estar seguros que la evolución de los enfermos (ej., su mortalidad a 5 años) no hubiera sido similar a la de una población sin la enfermedad (que en definitiva se puede morir con la misma frecuencia, aunque por otras causas)?
La condición ideal para que un grupo control sirva a estos propósitos es que sea comparable con el grupo expuesto. Mientras mayor sea la similitud entre los grupos, mayor es la posibilidad de que los resultados netos se deban a una asociación real entre la exposición y los resultados, y no a otros factores que también puedan explicar las diferencias encontradas. Cada tipo de diseño de investigación ofrece mecanismos para obtener grupos comparables (ej., asignación aleatoria, pareo [matching], estratificación).
Cuando no es posible obtener grupos suficientemente comparables, las técnicas estadísticas permiten dilucidar hasta qué punto una asociación existe, pese a las diferencias entre los grupos.
Relación causa-efecto
El hallazgo de una asociación a través de una investigación clínica no implica necesariamente que exista una relación de causa-efecto entre las variables.
Supongamos que decide estudiar si existe algún vínculo entre la religión que profesa un individuo y su nivel socioeconómico. Probablemente encontrará que diferentes religiones se asocian a distintos niveles de ingreso promedio, y que dicha asociación es estadísticamente significativa. ¿Significa eso que la religión asociada a menores ingresos es la causa del empobrecimiento relativo de esa gente? Difícilmente alguien podría sostenerlo.
Desde un punto de vista teórico, se afirma que, en rigor, los estudios clínicos no permiten establecer causalidad. Más allá de eso, usted puede formarse un juicio sobre la posibilidad de una relación causal entre las variables analizando si se cumplen las siguientes condiciones:
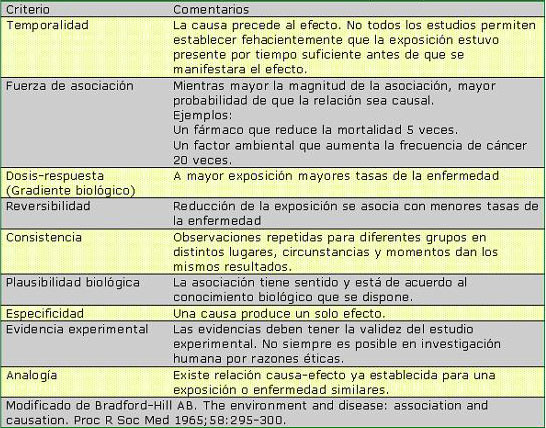 Tamaño completo
Tamaño completo Riesgo
Se define como la probabilidad de que un individuo desarrolle una enfermedad o presente otro desenlace en un período de tiempo dado. El desenlace puede ser adverso –morir, contagiarse- o beneficioso –desaparición del dolor, recuperación funcional. Hablamos de factor de riesgo (condición determinante, factor predisponente) para referirnos a cualquier atributo individual o exposición que se asocia –positiva o negativamente- con la ocurrencia de enfermedad u otro desenlace.
Un riesgo de muerte de 0,2 (ej., en un grupo de individuos en una cohorte) implica que ese grupo tiene un 20% de probabilidad de morir durante el período analizado, por ejemplo, 5 años (expresa una probabilidad acumulada a lo largo del período de tiempo).
¿Por qué citamos el riesgo aquí?
Porque a través de la diferencia en el riesgo observada entre los grupos, calculamos la magnitud de una asociación entre dos variables.
Para ello, lo que habitualmente se hace en primer lugar es medir el:
Riesgo Absoluto en cada grupo, es decir, la probabilidad observada o calculada del evento. Por ejemplo, imaginemos un estudio clínico sobre pacientes con infarto agudo de miocardio donde un Grupo A recibe Aspirina, un Grupo B recibe placebo, y el evento (desenlace, resultado) de interés es la probabilidad de muerte en el corto plazo (durante los 7 días siguientes al diagnóstico). El estudio revela que:
- Grupo A (aspirina): Falleció un 10% de los pacientes durante el período. El riesgo absoluto de morir en el grupo es de 0,1.
- Grupo B (placebo): Falleció un 20% de los pacientes durante el período. El riesgo absoluto de morir en el grupo es de 0,2.
Existe por lo tanto una aparente asociación entre el consumo de aspirina en estos pacientes y la probabilidad de morir (como hemos adelantado, demostrar la asociación exigirá realizar pruebas estadísticas y analizar los posibles errores del estudio). Veamos ahora cuál es la magnitud de esta posible asociación.
Una primera forma de hacerlo es calculando la diferencia absoluta de riesgo entre los grupos (reducción absoluta de riesgo [RAR], absolute risk reduction [ARR], absolute risk difference), que no es otra cosa que restar el riesgo en el grupo expuesto o tratado, al del grupo basal (no expuesto) o control.
En nuestro ejemplo:
Reducción absoluta de riesgo [RAR] = 0,2 – 0,1 = 0,1.
En términos absolutos, la aspirina redujo el riesgo de muerte en un 10% (si antes morían 2 de cada 10 pacientes, con la aspirina lo hará sólo 1).
La segunda es calcular la diferencia relativa de riesgo entre los grupos (riesgo relativo, relative risk [RR]), que no es otra cosa que dividir el riesgo del grupo expuesto o tratado, por el del grupo basal (no expuesto) o control.
En nuestro ejemplo:
Riesgo relativo [RR] = 0,1 / 0,2 = 0,5.
La aspirina redujo el riesgo de muerte a la mitad (con el uso de aspirina muere el 50% de los pacientes que lo haría sin ella).
Recuerde que el concepto de riesgo se usa en epidemiología clínica indistintamente para referirse a eventos negativos o positivos. Un riesgo relativo de 4 puede implicar, si las circunstancias del estudio son esas, que el “riesgo” de sanar en los pacientes que recibieron el tratamiento es 4 veces mayor que los que no lo hicieron.
Los artículos de la Serie "Introducción a la Medicina Basada en Evidencias" provienen del curso Introducción a la Medicina Basada en Evidencias y a la Investigación Clínica. Si le interesa ahondar en estos contenidos, le invitamos tomar el curso en el siguiente link.
