Artículo de revisión
← vista completaPublicado el 4 de enero de 2022 | http://doi.org/10.5867/medwave.2022.01.002528
Respondent-driven sampling: ventajas e inconvenientes de un método de muestreo
Respondent-driven sampling: Advantages and disadvantages from a sampling method
Resumen
Este artículo resume algunas consideraciones, ventajas e inconvenientes de esta técnica de muestreo conocida como Respondent-driven Sampling (RDS). Se señalan algunas críticas que han aparecido en la literatura científica respecto a la viabilidad de los supuestos inherentes a esta técnica y, en consecuencia, respecto a los estimadores puntuales y de las varianzas así obtenidas. También, se comentan los problemas observados en la literatura acerca de la calidad de los reportes de este tipo de estudios. Las encuestas que utilizan RDS deben ser metodológicamente de buena calidad, pues están siendo aplicadas extensamente para definir prioridades de programas sanitarios, para desarrollar políticas nacionales e internacionales de financiamiento de prestación de servicios, entre otras aplicaciones. Sin embargo, existe un amplio potencial de sesgo al usar este método, muchos de los cuales están relacionados con la implementación y los errores analíticos. La evidencia empírica sobre cuán representativos son los resultados obtenidos mediante RDS es limitada, y la búsqueda para mejorar la metodología es un área de investigación aún en progreso. No obstante, para tener confianza en los resultados publicados debe verificarse que la estructura social de las redes estudiadas se ajusta a los supuestos requeridos por la teoría de RDS, que los supuestos del muestreo se cumplen razonablemente y que la calidad del reporte es óptima, en particular respecto a los ítems metodológicos y analíticos.
Ideas clave
|
Introducción
Para abordar las diversas limitantes del estudio de las poblaciones ocultas o de difícil acceso, se desarrolló el Respondent-driven Sampling (RDS). Este es un método de muestreo no probabilístico que se aproxima al diseño de muestras probabilísticas permitiendo hacer inferencias en esta población [1] .
El término “población de difícil acceso” comenzó a utilizarse a principios de la década de los noventa en el ámbito de la salud púbica, para referirse a aquellos grupos de la población con menor nivel socioeconómico, a las minorías étnicas, de bajo nivel de alfabetización y que no son alcanzados de manera efectiva por las campañas comunicacionales de salud [2].
Los investigadores de las ciencias sociales acuñaron el término ”población oculta” [3] para designar aquellos grupos para los cuales no existe un marco muestral. Esto puede ocurrir en diversas situaciones, ya sea, por pertenecer a grupos sociales estigmatizados (hombres que tienen sexo con otros hombres), por presentar conductas ilegales (usuarios de drogas inyectables) o simplemente por ser grupos muy pequeños, entre otros.
En este trabajo, se presenta un resumen de los métodos de muestreo alternativos dirigidos a las poblaciones de difícil acceso u oculta. Además, se profundiza en fortalezas y bases teóricas de la estrategia de muestreo RDS, su implementación y supuestos del modelo y estimadores. Asimismo, se aborda el análisis de los datos, calidad de los reportes, el uso de esta estrategia para el estudio de algunas poblaciones de difícil acceso. Por último, se reconocen algunas críticas para su capacidad inferencial.
Métodos de muestreo alternativos
Las técnicas estándar de muestreo requieren que el investigador seleccione la muestra de manera tal, que cada miembro de la población objetivo tenga una probabilidad conocida, no nula, de ser seleccionado [4]. Este requisito significa que los investigadores deben tener un marco muestral, es decir, una lista de todos los miembros de la población objetivo. La imposibilidad de obtener muestras probabilísticas con “poblaciones ocultas” impulsó el desarrollo de métodos alternativos. A continuación, se señalan y describen brevemente las principales características de algunas técnicas de muestreo aplicada para la investigación de poblaciones ocultas o de difícil acceso:
- Muestreo de bola de nieve [5]: es un tipo de muestreo de referencia en cadena, utilizada con frecuencia en la investigación sociológica cualitativa sin fines inferenciales. El método produce una muestra a través de referencias realizadas entre personas que comparten o conocen a otros que poseen algunas características que son de interés para la investigación.
- Vigilancia centinela basada en instalaciones: corresponde a un tipo de muestreo que ha sido aplicado en poblaciones involucradas en actividades ilegales, como por ejemplo en instituciones correccionales de personas que usan drogas ilícitas o que ejercen comercio sexual [6].
- Muestreo a través de informantes clave: está diseñado para reducir los sesgos de respuesta mediante la selección de personas especialmente conocedoras del tema en estudio, a quienes se les pregunta sobre el comportamiento del grupo de interés, en lugar del suyo propio [7].
- Muestreo basado en sitios y horarios específicos (Venue Based Time-location sampling): es un tipo de muestreo, cuya característica principal es que previo al levantamiento de datos, se realiza un trabajo de campo (mapeo etnográfico) para construir un marco muestral que identifique los tiempos, cuando los miembros de la población oculta se reúnen en un lugar específico [8].
- Muestreo selectivo (Targeted sampling): intenta apartarse de los muestreos en poblaciones cautivas, institucionalizadas. Utiliza una serie de diferentes técnicas de divulgación, con la intención de atraer personas de una población oculta en un área urbana determinada (street-based outreach) [3].
Todas estas técnicas alternativas al muestreo probabilístico aleatorio son consideradas muestras por conveniencia. En consecuencia, sufren de sesgos de selección que imposibilitan la obtención de estimadores no sesgados de la prevalencia de las enfermedades estudiadas y de sus factores de riesgo.
Respondent-driven Sampling
Bases teóricas
El RDS es una técnica de muestreo de referencia en cadena, desarrollada por Douglas Heckathorn en los años noventa. Para aclarar, los métodos de referencia en cadena son aquellos mediante los cuales se obtiene una ruta de seguimiento de datos de una persona a otra, sobre la base de la relación entre ellos de forma consecutiva. Así se constituye una cadena que permite visualizar una relación de los diferentes individuos [9].
El método RDS combina aspectos del muestreo de bola de nieve y aspectos analíticos basados en el modelamiento estocástico de cadena de Markov y la teoría de las redes sesgadas (modelo de homofilia) [1]. Al igual que las técnicas de referencia en cadena, los autores se basan en la teoría que describe el fenómeno del “mundo pequeño”. Según él, al interior de cualquier red, no importando el tamaño, cada persona se asocia indirectamente con otra persona a través de seis intermediarios aproximadamente [10]. Esto significaría que incluso los individuos socialmente más aislados, pueden ser alcanzados en la sexta ola de una cadena de referencia, que comienza con cualquier individuo elegido arbitrariamente. Otras bases teóricas provienen de la sociología, en particular, de teorías conductuales que estudian la obediencia o el control social que puede basarse en la sanción o puede ser mediado por el grupo de pertenencia [11]. De ahí proviene la idea del incentivo y de la participación de los pares en el reclutamiento.
La teoría estadística en la que se basa el RDS se explica en profundidad en el artículo seminal de Heckathorn publicado en 1997 [1]. En resumen, existen dos teoremas relativos a los procesos regulares de Markov que se aplican al RDS. El primero establece que a medida que las cadenas de reclutamiento se alargan, la estructura de la muestra se vuelve menos dependiente de las semillas seleccionadas inicialmente, superando así cualquier sesgo que la elección no aleatoria de las semillas pueda haber introducido. El segundo establece que la muestra generada con RDS se acerca al equilibrio con rapidez geométrica. El autor reivindica que este método puede aproximarse al diseño de muestras probabilísticas, permitiendo hacer inferencias en poblaciones ocultas o difíciles de alcanzar. Esto es, que se pueden derivar indicadores no sesgados, así como estimadores de su precisión. Ello sería posible, siempre y cuando se consiga modelar con suficiente detalle el proceso de muestreo no probabilístico. En otras palabras, el RDS permitiría acercarse a un muestreo probabilístico simple a través de un paso intermedio. Este paso consiste en reconstruir la composición de la población mediante la información de las redes personales de los participantes (Figura 1).
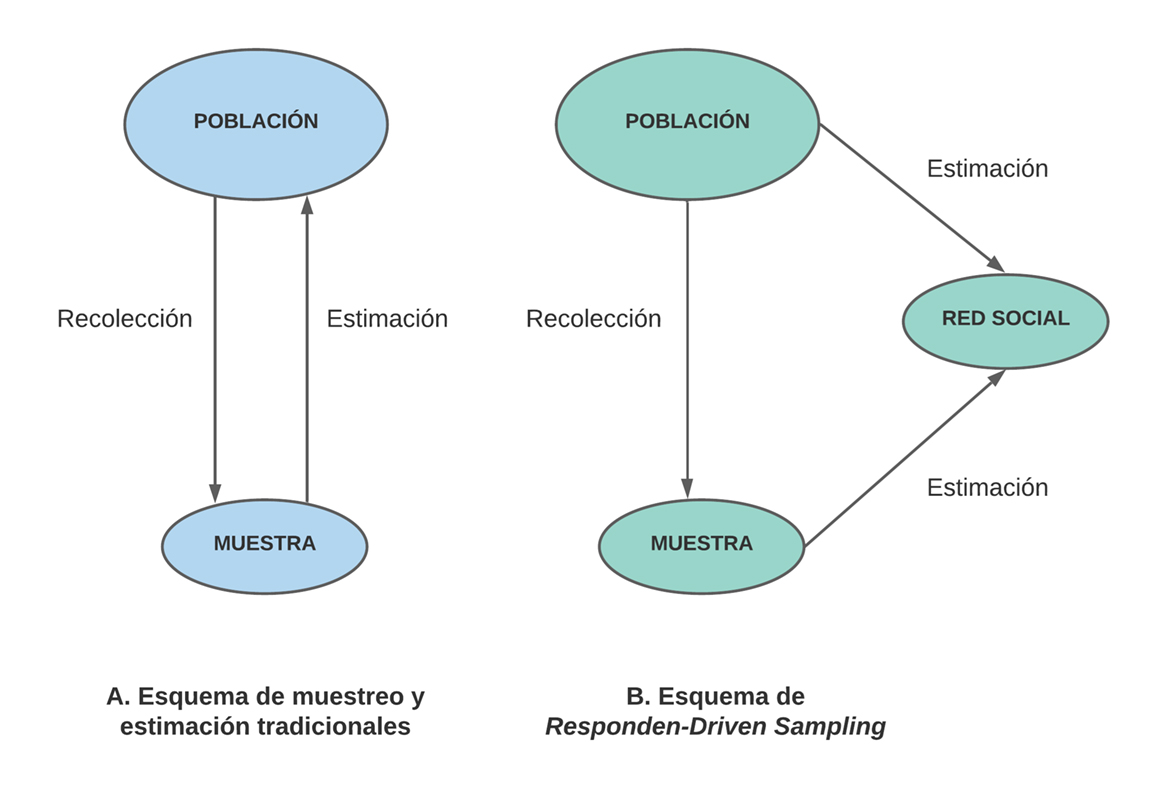 Tamaño completo
Tamaño completo La comprobación de la adecuación de modelo ha sido efectuada con datos de estudios empíricos y en simulaciones computacionales con resultados desiguales [12],[13],[14]. Este aspecto será profundizado más adelante.
Implementación
Operacionalmente, el reclutamiento del RDS comienza con la selección intencionada (no aleatoria) de cierto número de participantes iniciales o semillas, provenientes de la población objetivo. El conjunto de las semillas puede denominarse “ola cero”[1]. No obstante, se recomienda que las encuestas que utilizan esta herramienta cuenten con investigación previa denominada “evaluación formativa”. La evaluación formativa es una investigación realizada antes de que comience el muestreo y la encuesta propiamente tal. Los investigadores llevan a cabo grupos focales, entrevistas en profundidad, mapeo de la población objetivo y de las personas que trabajan con ellos, cuando sea el caso, para aprender más antes de que comience la encuesta [15].
Una vez que la semilla completa las actividades propias del estudio, se le compensa con un “incentivo inicial” y luego se le pide que reclute un número predeterminado de pares (generalmente de dos a tres) usando cupones. La semilla es recompensada con un “incentivo secundario” si los pares a quienes le entregó los cupones son reclutados exitosamente [15]. Los nuevos incorporados reclutan otros, a los que se les ofrecen los mismos incentivos iniciales y secundarios. De esta forma se genera una cadena de olas sucesivas hasta la saturación o hasta completar el tamaño de muestra deseado [15]. El uso de cupones que identifican a los reclutadores y a los enrolados mediante códigos alfanuméricos únicos, implica que no se recolecten datos personales. Ello asegura la confidencialidad de la identidad de los participantes, facilitando así el reclutamiento de personas naturalmente celosas de mantener su anonimato [15].
En los primeros años en que se comenzó a utilizar el RDS, en algunos estudios se presentó un grado de confusión y se tendió a denominar erróneamente un muestreo de este tipo siendo en realidad bola de nieve, aspecto que fue necesario clarificar. El RDS se diferencia de la técnica de bola de nieve en dos aspectos importantes. Primero, el RDS entrega incentivos a los participantes por participar y también por reclutar nuevos participantes, en tanto que bola de nieve sólo da incentivo por participar. Segundo, en el RDS los reclutados invitan personalmente a los nuevos participantes, mientras en bola de nieve los reclutados sólo identifican a los potenciales nuevos participantes, los que son luego contactados por el equipo investigador [1],[8].
Los autores de RDS sostienen que estas diferencias otorgan las siguientes ventajas: disminuyen el sesgo de masking que consiste en proteger personas elegibles (por ejemplo, amigos) no reclutándolos. Además, disminuye el sesgo de “voluntariedad” que ocurre cuando las personas se autoseleccionan para participar en una investigación. Igualmente, se argumenta que el uso de un número limitado de cupones por participante restringe la posibilidad de una sobrerrepresentación de aquellos con redes más extensas [1]
Recientemente se han desarrollado y llevado a la práctica encuestas RDS desplegadas en internet (webRDS), donde el reclutamiento se lleva a cabo por correo electrónico, seguido de una encuesta que se completa en un sitio web designado [12],[16],[17]. Considerando los sesgos potenciales del RDS, es difícil asegurar la calidad y veracidad de los datos a través de su aplicación en línea, aun cuando sea implementado en las mejores condiciones posibles. Por el momento, la experiencia es limitada y tendrá que pasar por evaluaciones acuciosas que validen esta modalidad.
Supuestos del modelo y estimadores
Para hacer estimaciones a partir de una muestra generada por los propios reclutados debemos, en primer lugar, asumir ciertos supuestos sobre la población en estudio y la forma en que se produce el reclutamiento. Al hacer explícitas estas suposiciones, permitimos que se pongan a prueba y que se investigue sobre la naturaleza del sesgo introducido cuando ellas no se respetan. Los supuestos iniciales, descritos por los autores del método [8] eran:
- Los reclutados se reconocen entre sí como miembros de la población objetivo, por lo tanto, los lazos son recíprocos. Un ejemplo de población oculta no apta al uso de RDS sería la población que evade impuestos pues no están naturalmente interconectados.
- Los reclutados están ligados por una red con un único componente. Esto significa que los lazos deben ser lo suficientemente densos para sostener la cadena de referencias.
- El muestreo ocurre con reemplazo, de forma que los reclutamientos sucesivos no mermen el grupo de posibles reclutados futuros.
- Los reclutados informan de manera exacta el tamaño de su red personal, entendida como el número de parientes, amigos o conocidos que cumplen con la definición de la población objetivo. Este supuesto es esencial pues con esta información se reconstruye probabilísticamente la red de cada participante.
- Los reclutados son seleccionados aleatoriamente entre los miembros de la red del reclutador.
- Cada reclutador, enrola a uno solo de sus pares al interior de su red.
Algunos de estos supuestos han evolucionado en el tiempo. Por ejemplo, la necesidad del supuesto número 6 desapareció al incorporar ajustes respecto del sesgo asociado al reclutamiento diferencial. Pero los principales supuestos, que son el corazón de la teoría que sustenta el RDS (supuestos 1, 4 y 5), son supuestos muy fuertes que necesitan ser verificados. Esto pues si los datos indican que han sido violados, las inferencias extraídas pueden no ser suficientemente fiables.
Análisis
El análisis de los datos generados con RDS tiene dos vertientes. La primera es el análisis dinámico de la muestra obtenida. La segunda, ocurre luego de que se alcanzó el tamaño de muestra deseado y consiste en el cálculo de los estimadores de las variables de interés, sus intervalos de confianza y el efecto de diseño.
En las técnicas de referencia en cadena, en particular con RDS, es necesario monitorear estrechamente la evolución del reclutamiento, no sólo respecto a su tamaño, sino también respecto a su evolución hacia el equilibrio. Explicaremos esta noción más adelante.
El monitoreo de la incorporación se realiza con la ayuda de gráficos que representan el árbol de reclutamiento producido con cada nueva ola. Estos gráficos permiten ir identificando las semillas improductivas, ayudan a definir la necesidad de iniciar nuevas semillas o aumentar el incentivo para integrar a grupos subrepresentados. Otra herramienta útil son los gráficos que permiten visualizar, ola por ola, cuando la muestra se aproxima al equilibrio. Ello permite interrumpir las cadenas de manera coordinada y armoniosa.
El análisis de la muestra obtenida consiste en verificar que la composición de la muestra alcanzó el equilibrio y que el nivel de homofilia de los grupos es adecuado. Estos aspectos se explican a continuación:
Equilibrio
Se refiere a la verificación respecto a si el modelo de Markov se ajusta a los datos (diagnóstico del modelo). Esto se realiza empíricamente mediante la comparación entre la composición de la muestra obtenida y la composición de la muestra teóricamente esperada, bajo el supuesto de que el muestreo corresponde a un proceso de Markov. Esto se denomina equilibrio. Más concretamente, el equilibrio se alcanzaría cuando la composición muestral de cada ola adicional se mantiene estable [1]. Se considera que se ha aproximado aceptablemente al equilibrio cuando la discrepancia es inferior al 2% entre el equilibrio teórico calculado y la composición actual de la muestra en cada uno de los subgrupos constituyentes de la muestra (por ejemplo, raza, género, localización, entre otros).
Homofilia
Es la tendencia a reclutar participantes que integran el mismo grupo de pertenencia. Una homofilia perfecta corresponde a la situación en que todos los lazos se forman al interior del grupo (se asigna un valor de + 1).Su contrario se llama heterofilia y ocurre cuando todos los lazos se forman fuera del grupo (se asigna un valor de - 1) [18]. Grupos con alta homofilia tenderán a ser sobrerrepresentados en la muestra obtenida, por lo que deben ser ponderados mediante técnicas estadísticas de post estratificación.
Finalmente, el análisis estadístico inferencial de los datos obtenidos involucra calcular los estimadores puntuales de la característica de interés (prevalencia, proporción de factores de riesgo en la población). Esto se lleva a cabo utilizando alguno de los métodos de ajuste desarrollados por los investigadores teóricos del área de RDS. Los distintos abordajes utilizados por cada uno no son objeto de esta revisión. Baste saber que los más conocidos son tres: el primero, identificado por sus siglas RDS-HK1 [18] fue refinado más tarde para RDS–I [8]. El segundo, conocido como RDS-II surgió en 2008 [19]. El más reciente, RDS-SS, fue desarrollado para reducir el sesgo introducido cuando el supuesto de muestreo sin reemplazo no es respetado. Esto es, cuando la fracción de muestreo es grande [13].
En lo que respecta al cálculo de los intervalos de confianza, Heckathorn propuso un método en 2002 que utiliza una forma especial de bootstrapping que toma en cuenta las diferencias en homofilia existentes entre los grupos. Vale la pena notar que a medida que el nivel de homofilia aumenta, el error estándar aumenta exponencialmente. Asimismo, cuanto más aumenta el error estándar más aumenta el tamaño de muestra necesario [18].
Respecto a los estimadores de varianza, se han desarrollado estimadores asociados a los estimadores puntuales indicados anteriormente. Por ejemplo, en Salganik Boostrap-Sal-BS [20] se usa típicamente con los estimadores puntuales RDS-I y II, en tanto en Succesive Sampling Bootstrap-SS-BS se usa con el estimador puntual de RDS-SS [13].
A partir de los estimadores de varianza-bootstrap, se pueden calcular intervalos de confianza de dos maneras: el método del percentil, que puede generar intervalos asimétricos en torno al estimador puntual, y el método de t de Student que produce siempre intervalos simétricos [21]. Los interesados en profundizar estos aspectos pueden consultar una revisión sistemática que resume los diversos estimadores puntuales y de varianza asociados a RDS [22].
Es importante subrayar que los datos obtenidos con RDS provienen de observaciones que no son independientes (concretamente, de redes o relaciones preexistentes). Por esto exigen técnicas específicas que son diferentes de las utilizadas con datos obtenidos mediante un muestreo probabilístico simple. Como vimos, existen diferentes métodos para calcular los estimadores puntuales y sus varianzas. Desafortunadamente, no existe consenso respecto a cuáles de los estimadores disponibles tienen las mejores propiedades, y mucha investigación está llevándose a cabo para mejorar la calidad de los estimadores [13],[14].
Softwares
Los creadores de la técnica de RDS desarrollaron un software, el RDS Analysis Tool (RDSAT, disponible en www.respondentdrivensampling.org) que permite monitorear el muestreo e implementar el análisis estadístico con facilidad. Otro software es RDS Analyst (www.hpmrg.org) creado por investigadores agrupados en la organización Hard-to-Reach Population Methods Research Group. Existen softwares, como NetDraw que permiten diseñar los gráficos de las redes conformadas durante el muestreo. Los utilizadores del software estadístico R pueden instalar el paquete Respondent-Driven Sampling recientemente desarrollado por Hard-to-Reach Population Methods Research Group. Todos los softwares mencionados están disponibles públicamente sin costo.
Es importante notar que, respecto del uso de softwares, la guía STrengthening the Reporting of OBservational studies in Epidemiology - Respondent-Driven Sampling, STROBE-RDS, (tratada más adelante), recomienda que “si se utiliza un software existente, proporcione el número de versión y la configuración de análisis específica utilizada con el fin de facilitar la interpretación de los resultados y la replicación de los métodos de análisis. Del mismo modo, si se utiliza programa escrito a la medida, el código debe ponerse a disposición de los investigadores que lo soliciten”. Es importante subrayar que no basta indicar el software usado, sino que se deben entregar los detalles de las especificaciones utilizadas. Por ejemplo, el menú del software puede solicitar el tamaño de la población, el número de iteraciones para el bootstrap, cuál de los estimadores escogieron para los cálculos, entre otros.
Usos y poblaciones reportados
Uno de los principales usos del muestreo RDS es la estimación de la prevalencia de alguna característica en la población. La técnica de este muestreo se aplicó inicialmente a grupos de personas con alto riesgo de infección por VIH, en particular a hombres que tienen sexo con hombres, usuarios de drogas inyectables y personas que ejercen comercio sexual. Posteriormente, se amplió el uso a otras poblaciones.
Últimamente, el RDS se ha utilizado ampliamente y ha obtenido el respaldo de organizaciones como los Centros para el Control y la Prevención de Enfermedades de los Estados Unidos [23]; el Programa Conjunto de las Naciones Unidas sobre el VIH/sida, ONUSIDA; la Organización Mundial de la Salud, el Fondo Mundial y otros. Estas instituciones lo han usado para establecer mediciones de referencia y tendencias de la prevalencia del VIH y otras infecciones, los comportamientos de riesgo, el impacto del programa a través de encuestas biológicas y de comportamiento. Otras poblaciones que han sido objeto de estudio mediante RDS son inmigrantes [24],[25],[26], músicos de jazz [27] y personas transgéneros [28].
Otros usos, como es estimar el tamaño de la población objetivo, han sido poco explorados [29]. Por el momento, el RDS no se recomienda para este propósito, especialmente si están disponibles opciones como el censo o captura-recaptura y los supuestos necesarios para su uso están justificados [30],[31].
Calidad del reporte de estudios que usan Respondent-driven Sampling
En 2015 se publicó una extensión de la guía STROBE [32], que es el estándar internacionalmente reconocido para el correcto y completo reporte de estudios observacionales en epidemiología. Esta extensión de STROBE para RDS [33] surgió como una necesidad, luego que un estudio exploratorio pequeño mostrara que las publicaciones que declaraban haber usado este método adolecían de deficiencias graves. Por ejemplo, los autores indicaban que sólo un tercio de la información exigida estaba presente, los elementos clave sobre el muestreo y el análisis de los datos carecían de detalles esenciales. Entre ellos se contaban el método de selección de las semillas, el número de reclutados por cada semilla, la formulación exacta de la pregunta sobre el tamaño de la red y cómo fueron capacitados los participantes para reclutar a sus pares, entre otros. Para adaptarse a los estudios que aplican RDS, los redactores de la guía STROBE-RDS introdujeron modificaciones en 12 de los 22 ítems del checklist de STROBE para estudios transversales. En la Tabla 1 se enumeran los 12 ítems agregados o modificados, con una breve explicación de los que se espera se indique en cada ítem.
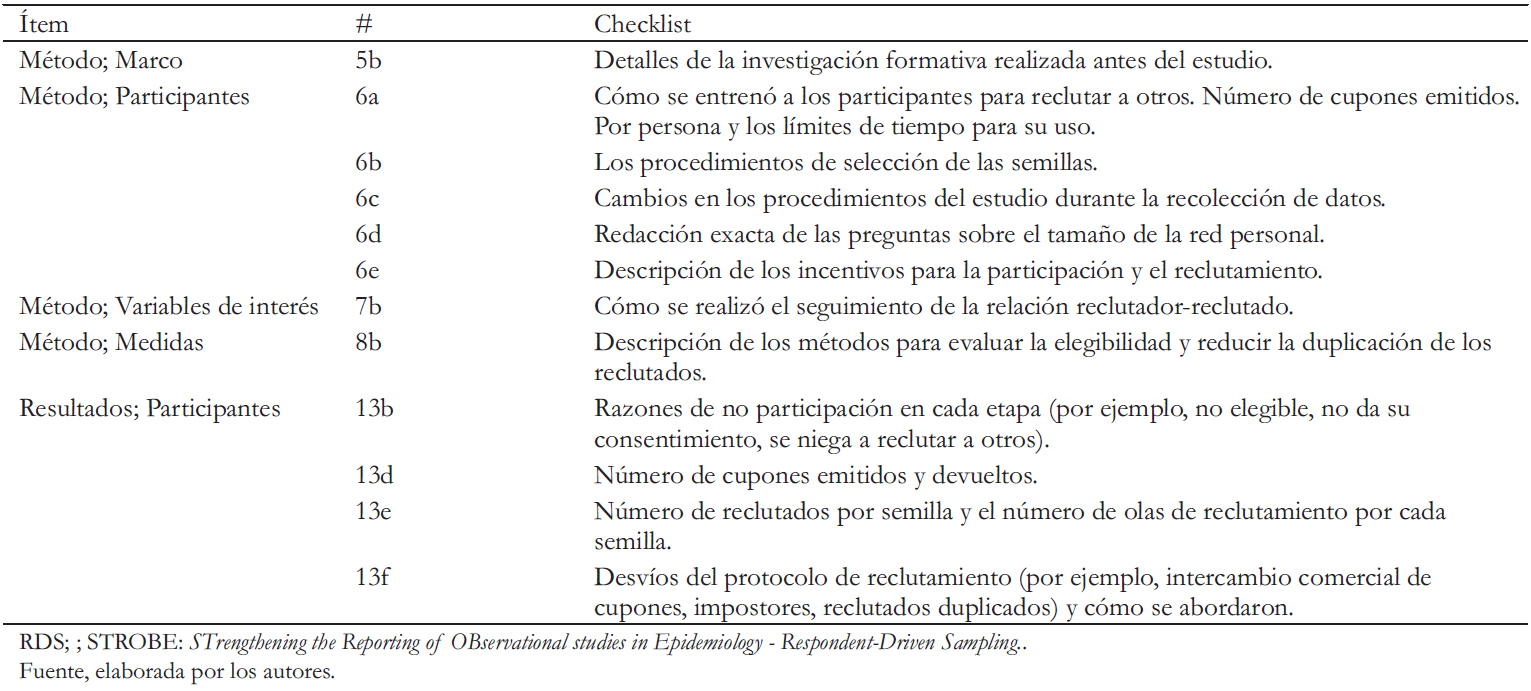 Tamaño completo
Tamaño completo Una revisión sistemática publicada en 2016 [34] se interesó en la calidad del reporte de los ítems esenciales definidos por STROBE-RDS, evaluando los estudios publicados hasta 2013 que declaraban haber utilizado RDS. La publicación además entrega un panorama de la extensión y diversificación de las aplicaciones de dicha herramienta en la literatura médica científica. La revisión sistemática identificó 151 artículos, en inglés, revisados por pares y cuyo objetivo era estimar una prevalencia (excluía los artículos metodológicos). Estos artículos describían 222 encuestas realizadas en cinco regiones del mundo.
Los autores son los mismos que lideraron el desarrollo de STROBE-RDS, por lo que sus conclusiones son muy similares. Ellos subrayan que la ausencia de información sobre los ítems metodológicos y analíticos del RDS, dificultan la evaluación de la calidad de los estudios y de la solidez de los resultados. Este método no es válido para todas las situaciones, y se deben detallar los esfuerzos realizados para cumplir con los supuestos. Por ejemplo, sólo 43% de las encuestas informaron del número máximo de olas y sólo 20% informó sobre si se alcanzó el equilibrio o la convergencia, datos que son necesarios para evaluar los posibles sesgos. La mayoría de los estudios incluidos en esta revisión sistemática provenían de Norte América y Europa, por lo que sería interesante ver resultados de otras regiones.
Críticas a la capacidad inferencial de Respondent-Driven Sampling
Con el aumento de la aplicación de RDS en una variedad de poblaciones en diferentes contextos y países, ha surgido escepticismo con respecto al cumplimiento en el mundo real de los supuestos del modelo que sustenta a este método de muestreo. Un problema frecuente se presenta cuando el proceso no consigue alcanzar el tamaño de muestra deseado, debido a que las cadenas se interrumpen después de pocas olas. Con frecuencia se intenta mitigar el efecto indeseado agregando nuevas semillas. Según Malmros, 43% de los estudios RDS revisados reportaban haber iniciado nuevas semillas [35].
Gile es un autor que ha publicado mucho respecto a la teoría que sustenta RDS. En el artículo donde propuso un nuevo estimador, que lleva su nombre, discute la noción de que los estimadores propuestos por Volz y Hackethorn [19] sean “asintóticamente no sesgados” [36]. Plantea que existen tres áreas principales en las cuales las desviaciones de las condiciones ideales pueden introducir sesgos. La primera, involucra la selección de las semillas por conveniencia; la segunda, abarca los aspectos conductuales del reclutador/reclutado; y la tercera, corresponde a los desvíos del modelo de random walk.
Un estudio relativamente reciente, que se llevó a cabo con usuarios de drogas inyectables [37], se propuso evaluar algunos de los supuestos subyacentes al modelo teórico de RDS. El gran mérito de este estudio es que los autores recogieron de manera muy escrupulosa datos sociométricos de las redes de los participantes. Además, se recolectó información detallada y en profundidad respecto al comportamiento de los reclutados y reclutadores. Es necesario recordar que uno de los supuestos centrales de RDS es que el reclutador selecciona sus pares aleatoriamente, al interior de su red social de contactos. Los autores observaron que casi la mitad de los participantes redistribuían los cupones en la calle, no se observaron patrones uniformes en el comportamiento de los reclutadores (al escoger y aproximarse a los reclutados, al pasar los cupones), ni de los enrolados (al aceptar/rechazar los cupones, al declinar su participación). Los autores concluyen que son transgredidos supuestos centrales del RDS. Entre dichos supuestos están la selección aleatoria, la probabilidad de reclutamiento proporcional al tamaño de la red del participante y el reclutamiento ocurriendo entre lazos recíprocos al interior de la red, entre otros.
Resumidamente, el problema sería que para utilizar los estimadores actuales se asume que los individuos muestreados responden siempre, que reclutan siempre a otros individuos cuando son solicitados y que reclutan al azar entre sus conocidos. En la práctica, los individuos muestreados pueden no responder (tasa de no respuesta), pueden no siempre reclutar a otros (efectividad imperfecta del reclutamiento) y pueden invitar preferentemente a personas con características particulares y no al azar (reclutamiento diferencial). Por ejemplo, si el incentivo es muy atractivo puede que enrolen preferentemente al interior de una familia (homofilia) o, al contrario, si la actividad en común es muy comprometedora pueden tender a reclutar desconocidos, violando así el supuesto de reciprocidad.
La mayoría de los sostenedores y también los críticos del RDS opinan que esta herramienta debe considerarse como una forma, potencialmente superior, al método de muestreo por conveniencia. Sin embargo, se requiere precaución al interpretar los hallazgos basados en este método de muestreo.
Conclusiones
Las encuestas que utilizan RDS deben ser metodológicamente de buena calidad, pues están siendo aplicadas extensamente para definir prioridades de programas sanitarios, para desarrollar políticas nacionales e internacionales de financiamiento de prestación de servicios, entre otros.
Sin embargo, existe un amplio potencial de sesgo al usar este método, muchos de los cuales están relacionados con la implementación y con errores analíticos. La evidencia empírica sobre cuán representativos son los resultados obtenidos mediante RDS es limitada. La búsqueda para mejorar la metodología es un área de investigación aún en progreso. Es esencial asegurar la transparencia y exactitud del reporte de estudios que utilicen RDS y así poder implementar el método con más confianza.
Existen muchos aspectos que han sido poco estudiados. En nuestra opinión, el tema de los incentivos necesita ser profundizado, pues no todas las poblaciones ocultas responden a incentivos monetarios de monto moderado y, probablemente, haya algunas que no responden a ningún monto. Igualmente, el tema del cálculo del tamaño de muestra necesario es confuso o, al menos, circular. Ello, debido a que, si no se conoce el tamaño de la población, no es posible hacer dicho cálculo. Del mismo modo, cuando se calcula el efecto del diseño también es necesario contar con la varianza que se observaría si se realizara un muestreo probabilístico simple. Es discutible recomendar un efecto de diseño igual a dos, como hacen los autores de STROBE-RDS, cuando las experiencias muestran una gran variabilidad. Por último, el tema del menor costo de los estudios realizados con RDS también merece mayor atención, pues si el efecto del diseño es dos, tres o más, esto significaría aumentar la muestra considerablemente. A ello hay que sumarle los costos de la investigación formativa previa, que hoy en día es considerada indispensable.
El RDS es un método de muestreo muy popular debido a que es un procedimiento eficaz para reclutar personas, que de otra manera podrían ser reacios a participar en una investigación. A falta de mejores métodos para alcanzar poblaciones ocultas, este tipo de muestreo seguirá utilizándose en el futuro. Es probable, que la existencia de softwares disponibles sin costo haya influido en el éxito, y la amplia propagación del uso de RDS. Sin embargo, para tener confianza en los resultados publicados se debe verificar que la estructura social de las redes estudiadas se ajusta a los supuestos requeridos por la teoría del RDS; que los supuestos del muestreo se cumplen razonablemente; y que la calidad del reporte sea óptima, en particular, respecto a los ítems metodológicos y analíticos.
Notas
Roles de autoría
MSN: conceptualización, metodología, investigación, preparación de manuscrito (desarrollo del borrador original). CA: conceptualización, investigación, redacción (revisiones y ediciones). VCB: conceptualización, metodología, supervisión, adquisición de fondos, investigación, revisiones y ediciones.
Financiamiento
Este trabajo contó con el financiamiento de la Universidad de Santiago de Chile (USACH), a través del Proyecto InvClínica _DICYT, Código 021991BNNC_MED, de la Vicerrectoría de Investigación, Desarrollo e Innovación.
Conflictos de intereses
Las autoras completaron la declaración de conflictos de interés de ICMJE y declararon que no recibieron fondos por la realización de este artículo; no tienen relaciones financieras con organizaciones que puedan tener interés en el artículo publicado en los últimos tres años y no tienen otras relaciones o actividades que puedan influenciar en la publicación del artículo. Los formularios se pueden solicitar contactando al autor responsable o al Comité Editorial de la Revista.
Aspectos éticos
Este estudio no requirió de la evaluación por parte de un comité de ética, debido a que trabajó sobre fuentes secundarias.
Idioma de la versión original
Español.
